RAG, Fine-tuning or both ?
Let me tell you something that'll save you months of wasted effort and a small fortune in compute costs. Right now, many teams I talk to are throwing money at fine-tuning models when they should be using RAG. The other half are duct-taping RAG pipelines together when fine-tuning would solve their problem in a weekend. And almost nobody is combining them, which is often the real answer.
We're all pretending we know which approach to pick. Most teams don't. Someone on the team read a blog post, got excited, and now the whole roadmap is built around a technique that doesn't fit the problem. I've seen it happen more times than I can count.
What Is RAG?
RAG stands for Retrieval-Augmented Generation.
Think of it this way. An LLM is like a brilliant consultant you just hired. They've read thousands of books and know a lot about the world. But they've never seen your company's internal docs, your product specs, your customer tickets. They're smart but completely clueless about your stuff.
RAG is how you fix that. Instead of retraining the consultant's brain (expensive, slow, painful), you hand them the right documents at the moment they need them. They read the relevant pages, then answer your question using that context.
That's it. That's RAG.
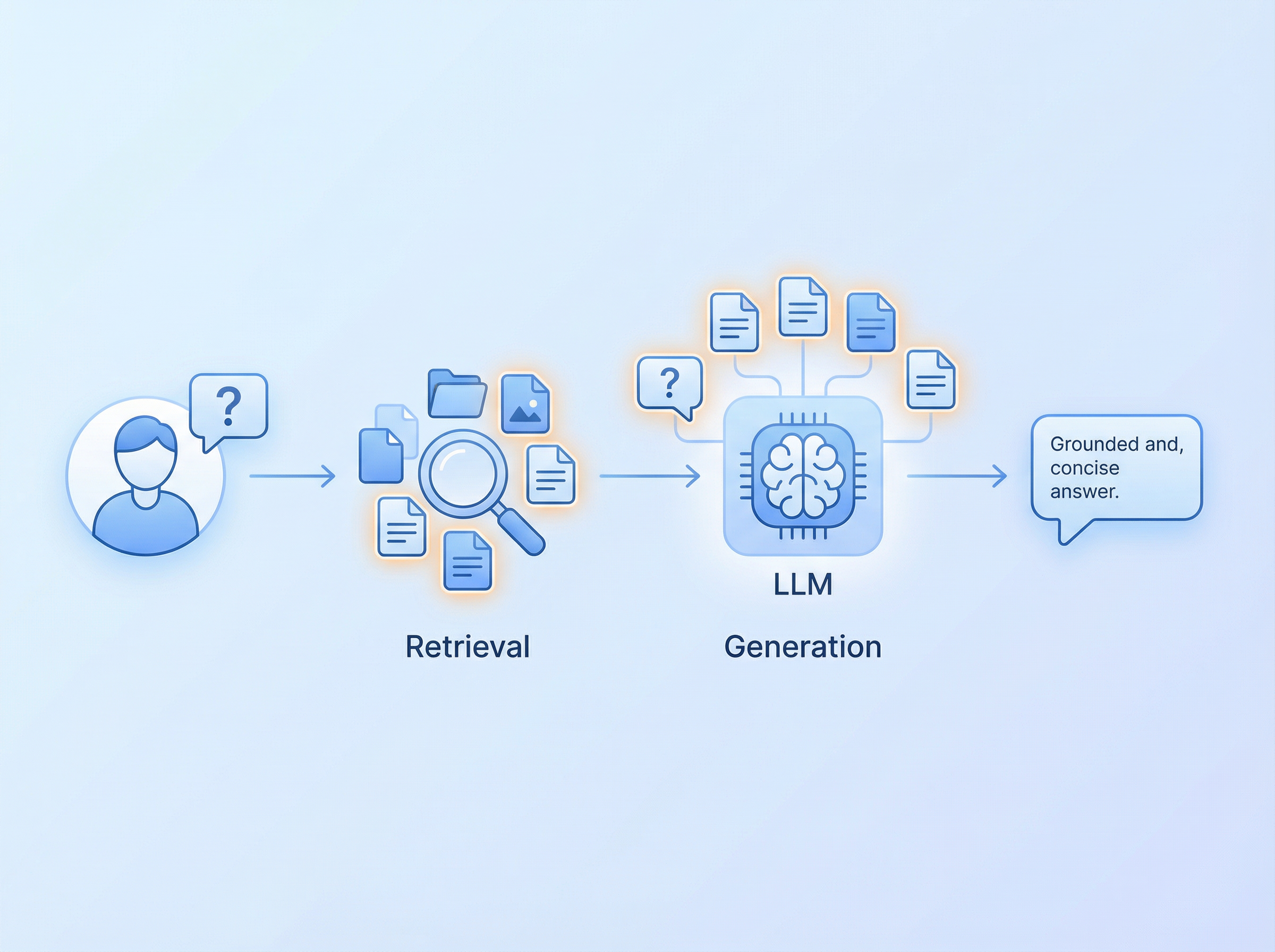
The system works in two steps:
Retrieve: When a user asks a question, the system searches your knowledge base (documents, databases, wikis, whatever) and pulls the most relevant chunks of information.
Generate: Those chunks get fed to the LLM alongside the user's question. The model generates an answer grounded in your actual data.
Simple. Not easy. But simple.
When RAG Is the Right Call
RAG is good when your problem is about knowledge, not behavior. Here's when you should reach for it.
Your data changes frequently. Product catalogs, legal regulations, support documentation, internal policies. If your knowledge base gets updated regularly, RAG just works. You update the documents, the system picks them up. No retraining. No waiting. No GPU bill that makes your CFO ask questions.
You need to point to where the answer came from. This one is huge and people overlook it all the time. With RAG, you can trace exactly which document the answer is based on. "This answer comes from Section 4.2 of your Q3 policy document." Try doing that with a fine-tuned model. You can't. The knowledge is baked into the weights. There's no paper trail.
You're working with proprietary or sensitive data. RAG lets you keep your data in your own systems. The documents live in your vector database, behind your firewall. The LLM never "learns" your data permanently. It just reads what it needs, when it needs it.
You need to get something working fast. A basic RAG pipeline can be up and running in days. I mean it. It's not trivial to make it great, but getting to a working prototype is fast compared to any alternative.
When Fine-Tuning Is the Right Call
Fine-tuning is a different game. Instead of giving the model new information at query time, you're changing the model itself. You're reshaping its behavior, its reasoning patterns, how it structures responses.
But let's be real about what fine-tuning actually costs you. You need quality training data, and a lot of it. The process takes weeks, not days. It burns through compute. And here's the part people don't think about enough: you're literally changing the model's weights. That's permanent. If your data was bad or your approach was off, you don't just "undo" that. You start over.
That said, there are times when it's the right move.
You need a very specific output format or reasoning style. If every response needs to follow a rigid JSON schema, or reason through problems in a particular domain-specific way, fine-tuning can lock that in. You're not teaching it new facts. You're teaching it new habits.
You need consistency at scale. RAG outputs can vary depending on what gets retrieved. If you need rock-solid, predictable responses across thousands of queries (same format, same depth, same structure), fine-tuning gives you that.
You want to make a smaller model punch above its weight. Take a smaller, cheaper model and fine-tune it to be exceptional at one specific task. You end up with something faster, cheaper to run, and often better at that narrow task than a general-purpose giant model. That's a real edge.
The knowledge is stable. If you're working with information that doesn't change (medical terminology, industry-specific reasoning patterns, established legal frameworks), baking it in through fine-tuning can be more efficient than retrieving it every single time.
When You Need Both
Most serious production use cases eventually need both. The teams that figure this out early have a massive head start.
Fine-tuning teaches the model how to behave. RAG gives it the knowledge to be accurate. These aren't competing approaches. They're complementary.
Quick example: you're building an AI assistant for a financial services company. You fine-tune the model so it responds in the right compliance-friendly tone, structures its answers the way your advisors expect, and reasons about financial concepts properly. Then you layer RAG on top so it can pull the latest market data, regulatory updates, and client portfolio information at query time.
The fine-tuned model knows how to answer. RAG makes sure it has the right information to answer with.
The combo makes sense when:
You need both domain-specific behavior AND up-to-date knowledge
You want a model that speaks your language but also references your latest data
You're building something that needs to be both consistent and current
You've outgrown basic RAG and need better reasoning over your retrieved documents
What We Did at Azerion
I'll give you a concrete example because theory only gets you so far.
When I was building the AI team at Azerion, we had a project for the finance and legal teams. They needed an AI system that could work with their internal documents: contracts, financial reports, compliance policies, the whole stack. Hundreds of documents, updated regularly, across multiple departments.
We had a choice to make. Fine-tune a model on all that data, or build a RAG system.
We went with RAG. And it wasn't even close.
Here's why. The finance and legal teams update their documents constantly. New contracts come in. Policies get revised. Regulatory requirements change. If we had fine-tuned a model, we'd be retraining it every time something changed. That's expensive, it's slow, and every time you retrain, you're messing with the model's weights. There's always a risk you degrade performance on things that were already working fine.
With RAG, when a new document drops or a policy gets updated, it goes into the knowledge base and the system picks it up. No retraining. No risk of breaking what already works. The legal team updates a contract template on Monday, and by Tuesday the AI is already using the new version. That's it.
The other big factor? Traceability. When the finance team asks a question and gets an answer, they need to know where that answer came from. Which document? Which section? RAG gives you that for free. With a fine-tuned model, the knowledge is just... in there somewhere. Good luck explaining to your legal team that the AI "learned it during training." That's not going to fly.
Our approach was simple: start with RAG, prove it works, get the teams comfortable with it. And then if they need more, if the model needs to reason differently or respond in a very specific format, we can explore fine-tuning later as an addition, not a replacement.
That's the key. RAG first. Fine-tuning if and when you actually need it. Not the other way around.
How to choose?
Stop overthinking it. Three questions:
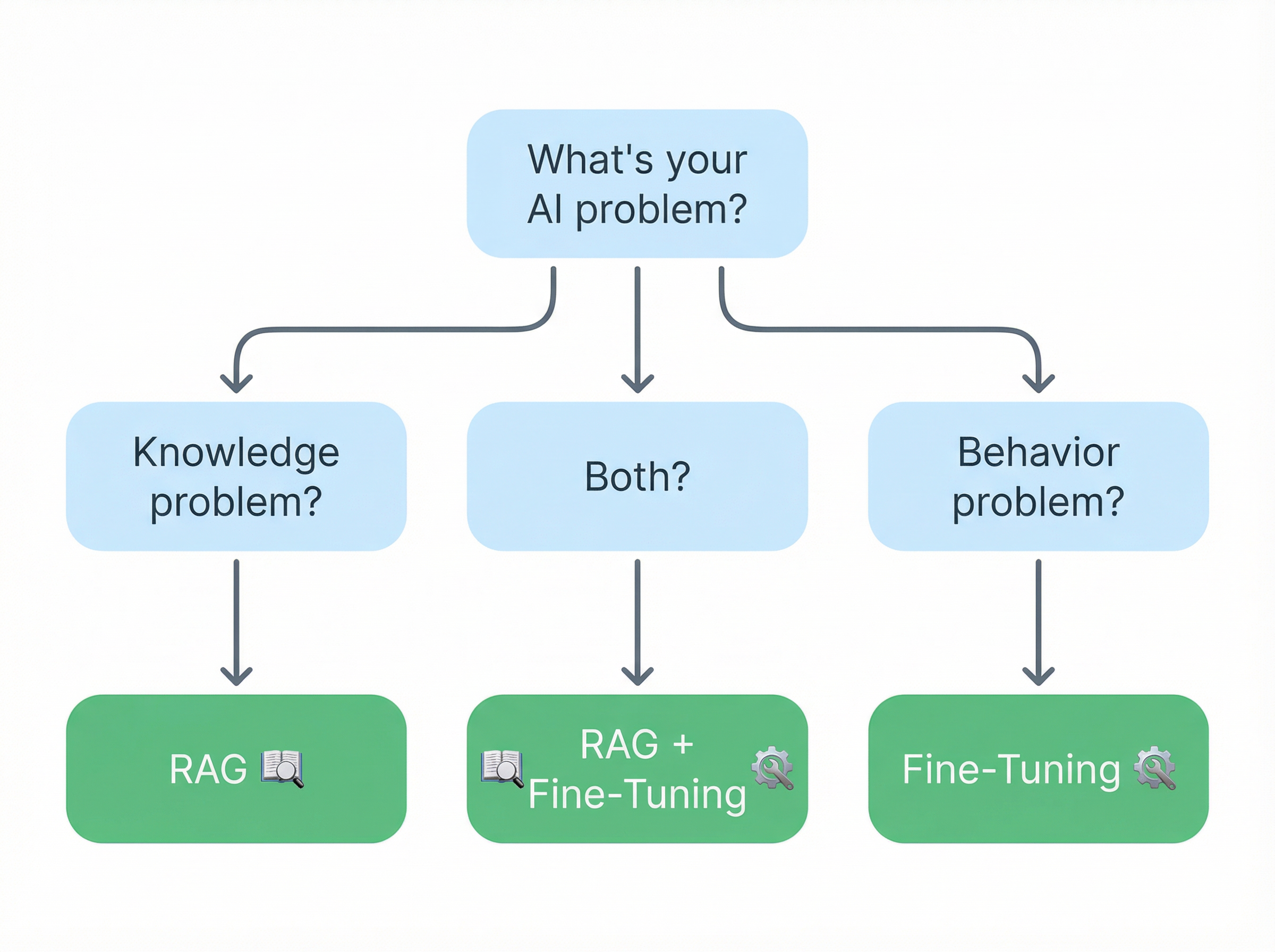
1. Is your problem about knowledge or behavior? Knowledge? RAG. Behavior? Fine-tuning. Both? You already know.
2. How often does your data change? Frequently? RAG has to be in the mix. You can't retrain every time your docs update. Rarely? Fine-tuning becomes more attractive.
3. How important is traceability? If you need to show where answers come from (legal, compliance, regulated industries), RAG gives you that out of the box. Fine-tuning doesn't.
If you're defaulting to fine-tuning because it sounds more sophisticated, stop. Start with RAG. It's faster to build, easier to iterate on, and way cheaper to maintain. You can always layer fine-tuning on top later when you actually understand what behavioral changes you need.
And if someone on your team is pushing to fine-tune a model before you've even validated the use case with a basic RAG prototype? Push back. That's not engineering rigor. That's building the most complex thing first and hoping for the best.
Build the simple thing. Prove it works. Then make it better.